背景
在现实的项目过程中,由于人员的更替,以及业务的发展,总是会导致一个问题,那就是流程细节的丢失,项目时间越久,这个问题越是严重。所以往往会出现产品在不知道这个功能的流程的情况下设计方案,开发在开发过程中才发现流程上的设计缺陷,这不仅仅导致了项目时间的推迟,更可能导致整个业务流程上出现漏洞而危害整个产品,如果是云音乐这种类型产生问题可能表现不大,但像考拉这种涉及到钱的项目严重的可能导致信任危机。
要解决这个问题传统的做法就是详细业务文档,这需要:
- 文档要求详细,并且在统一的地方维护
- 人员交接的时候,文档需要完整交接
- 多方(产品、开发、测试等)的信息同步
遗憾的是,这么多年的工作中,我没有发现一个项目能够做到这一点的,遇到问题只能人肉阅读代码。在目前国内企业的环境来看,要写一份详细完整的文档,也是几乎不现实的。
无论在哪种问题下,产品不了解流程,或是视觉不知道中间的弹窗,或是多方出现理解分歧,最终都是由开发阅读老代码来判断以前的流程是怎么样的,所以代码中的逻辑一般是最准确和详细的。在需求变更后,最先更新的也往往是代码(上帝也不能保证产品会把变革更新到文档)。
那么我们如果能从我们的代码逻辑中直接提取这个流程,并且通过流程图的形式展示出来,也就省去了很多一部分为别人服务的时间。而且拥有流程图之后我们也可以直观的检查我们的代码逻辑是是不是存在bug。
markdown有一个流程图表的功能,很多markdown编辑器也已经支持了,这给了我一个开发一个能够解决流程问题的思路。
mermaid
graph TD
简述
我们需要这个新的框架能够足够通用,能够适用于大部分场景。
每个流程需要足够的独立,不能依赖太多的外部信息,能够复用和自由组合。
可以输出可读性强的流程信息,比如markdown等。
有一定的自检能力,保证整个流程的完整性和正确性。
这里我们用一个最简单的点赞流程来解决:
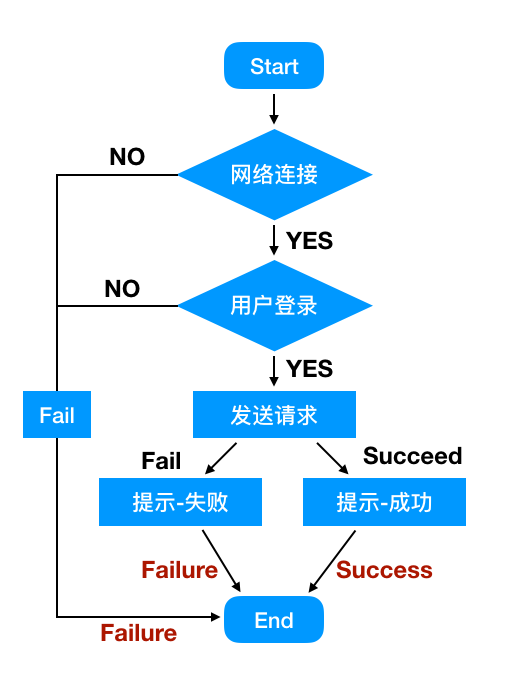
实现
1. 结构
1.1 状态 State
我们在看流程图的时候,把一整个流程拆分为一个个节点的时候,可以看到每个节点(状态)都可以抽象为拥有一个输入,多个输出的结构:
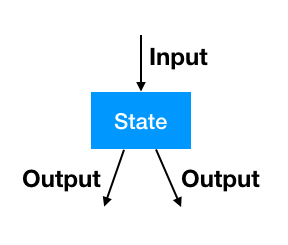
每个具体状态必须只做一件事情,每个条件分支也必须为一个独立的状态。
1 | if (isLogin) { |
需要抽象为:
1 | StateIsLogin --> |isLogin| login |
多个状态可以组合成为一个复杂的状态,这个复杂的状态其行为依然和最简单的状态一致。当我们最终组合而成的点赞功能,也应该是一个状态机,拥有一个输入和多个输出。
1.2 规则 Rule
不同的状态之间,是通过某种规则进行连接。
最简单的规则就是执行下一步,最普遍的规则就是匹配上一个状态输出的结果。
为什么这里要加入个规则的概念,而不是直接建立状态直接的依赖关系?主要原因有:
- 设计上更简单、明确,通用性更强,我可以自定义规则来实现一些多参数的匹配等
- 条理更清晰,可以方便的转化、输出文档
- 可以集中化管理,可以方便的跟踪当前状态的变更
1.3 组合
这里演示为了代码的可读性,所以采用了c++,实际使用的时候语言并不是阻碍。
所有的状态创建统一通过工厂创建:
1 | auto b = Builder(ctx); |
那么上述一个简单的点赞流程可以写作:
1 | b.start() |
那么我们最终得到的状态机可以在需要的时候启动:
1 | [praiseMachine startWithParams:@{@"test": @"Test Value"}]; |
这里就不再描述具体结构了,详细可以看我的demo
1.4 纯粹性/原子性
一个状态在被使用过后,可能会产生很多垃圾,会污染了这个状态的内部。反之我们可以定义在执行前后不会发生变化的状态为纯状态。
如果我们的子状态机都是纯状态,那么我们组合而成的状态机也必然是纯状态。
纯状态的一个好处就是可以被反复使用,而不需要重新创建,减少创建的开销,以及提前创建流程状态机。
2. 输出文档
我们把结构改成状态机虽然能够在代码流程上更为清晰,但也会增加学习成本和代码量,单纯这么做的意义并不大,所以我们需要将这个流程以更可见的形式输出。
某些markdown编辑器集成了流程图的语法,我们刚好可以借助这个功能。下面我们将我们的结构格式化后打印出来:
1 | DDStateMachineMarkdownWriter *writer = [DDStateMachineMarkdownWriter new]; |
打印结果是
1
2
3
4
5
6
7
8
9
10
11
12
graph TD
DDBlockStateMachine1(网络连接) --> |YES| DDBlockStateMachine2(用户登录)
DDBlockStateMachine1(网络连接) --> |NO| DDContinueStateMachine1(End)
DDBlockStateMachine3(点赞请求) --> |success| DDBlockStateMachine4(提示)
DDBlockStateMachine3(点赞请求) --> |failure| DDBlockStateMachine5(提示)
DDContinueStateMachine2(Start) --> DDBlockStateMachine1(网络连接)
DDBlockStateMachine5(提示) --> DDContinueStateMachine1(End)
DDBlockStateMachine2(用户登录) --> |NO| DDContinueStateMachine1(End)
DDBlockStateMachine2(用户登录) --> |YES| DDBlockStateMachine3(点赞请求)
DDBlockStateMachine4(提示) --> DDContinueStateMachine1(End)
复制到markdown编辑器中,可以转化为流程图:
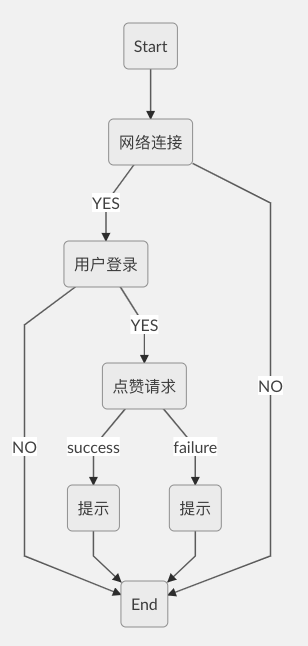
当然这只是一种导出方式,我们可以自行设计更好的导出方式。
我们可以通过比对流程图,来看我们修改的逻辑流程是否发生了正确的改动。
甚至我们可以在自动化测试脚本中加入流程的验证,或者控制流程的走向。
在线上我们也可以用于记录用户操作,是在什么环节出现了错误导致本次流程的失败或者撤销。
3. 状态跟踪
当我们把流程封装成一个状态后,就相当于一个黑盒系统了,我们无法在这个流程中插入一些额外的非流程内的东西了,比如统计埋点等。
这里我们需要给外部系统提供一个状态跟踪的能力,当触发这个状态变更的时候给予外部一个信号或者执行一段代码,具体能力可以依据需要实现。这也是上述为什么要设计Rule这一结构的原因之一。
以上的流程代码可改为:
1 | checkLogin |
那么我们就可以去监听@”login”这个信号,在请求成功后就会自动触发。比如在这里增加一个埋点信息。(关于埋点,我们后续可以再讨论一篇)
比如打印信息:Machine (用户登录) will goto (点赞请求) with log (login)
4. 完整性检查
另一个开发中比较容易出现的问题就是对异常和特殊情况的判断,这个问题在传统的开发中并没有什么特别有效的方法去避免,只能靠个人能力和测试的完备。
一个简单的例子就是,我们会在请求之后判断成功而更新UI,但会比较容易忽略失败的场景,而对于某些场景我们还是需要去处理失败的。
而在这种新的结构下,我们就比较容易做这个检查了。
我们需要在强制检查的状态中指定可能会返回的结果:
1 | machine.validResults = @[Result::Yes, Result::No]; |
然后去检查可能的结果是否都已被Rule处理了:
1 | NSError *error = nil; |
如果发现缺失,则会输出哪一个状态的哪一条规则缺失:Error: <DDBlockStateMachine> 用户登录 do not obey result(YES);。
这样我们就可以强制开发者必须保证逻辑流程的完整性,以防止我们在不经意间引入一些问题。
总结
以上几个能力是我觉得在现实的场景中比较重要的,现实项目中,特别是大型项目,人员流动频繁,有些时候整个业务都可能会进入一个不可控的场景,这时候我们不能保证外部给我们信息是完整的,也不能保证内部人员足够的熟悉项目的细节,那么只能从架构上进行约束,将很多流程规范化,结构化,进行强校验才是解决这类问题的方法。
采用新的架构也必然会导致整个学习成本的上升,同时也要求整体人员的水平能够从更高的角度去看待问题,能够去理解这么做的原因和原理。
约束并不是目的,而是在约束下我们能更好的保证质量。