CPU在我们不知道的情况下做了很多的优化,下面我们就来看看。
Case
如下,有一个n长度的数组,内容为0~256的随机数。
1 | int array[i]; |
如果该数组是一个排好顺序的数组,那么同样条件下执行该逻辑。
我们会发现排序的会比未排序的执行效率高很多,甚至是其几倍的关系,这是为什么呢?
这就涉及到CPU在执行条件语句的时候所做的优化了,也就是分支预测。
Why?
分支预测是指在执行条件分支前,就去猜测其条件结果。其目的是为了提升CPU流水线的执行效率。在现代CPU中,分支预测扮演着一个非常重要的,提升效率的角色。
如果没有分支预测,那么CPU需要等待条件执行完后才能知道下一步的跳转地址。为了消除之间的等待时间,CPU会去预测其条件结果,是更倾向于true,还是更倾向于false。在预测错误的情况下,需要忽略之后的指令,并且重新加载正确的指令。
重新加载指令所造成的时间浪费取决于流水线架构CPU的层级。比如下图最简单的4级流水线。现代CPU往往拥有非常大的流水线级别,很容易造成10~20时钟周期的浪费。所以就更需要更智能的分支预测了。
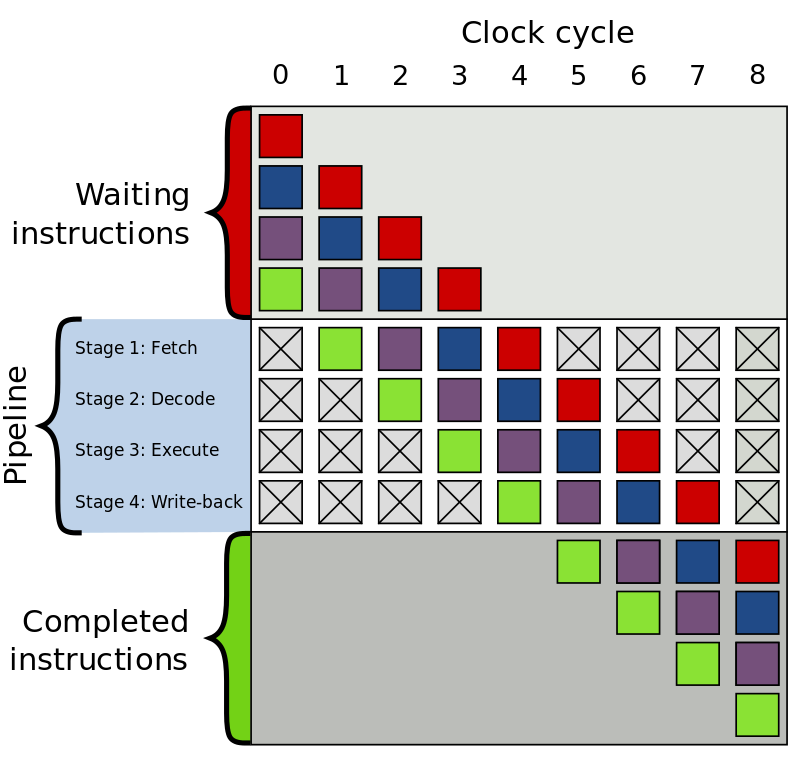
流水线架构
流水线架构CPU在执行指令的时候一般有如下几个过程:
- 取指 Fetch
- 译指 Decode
- 执行 Execute
- 回写 Write-back
Static branch prediction / 静态分支预测
静态分支预测是一个非常简单的策略,不依赖执行环境和执行过程中的状态。比如某些CPU,总是会预测一个条件是false的,有些则会对向前条件和向后条件做不同的预测,甚至有些架构允许插入预测代码。但总的来说,静态预测永远是编译器就已经做好了。
Dynamic branch prediction / 动态分支预测
动态分支预测则是在运行期间来决定我们的预测结果。接下来我们要分析的均是动态分支预测。
前提
在做分支预测前,我们所确定的是,所有分支都是有偏好的,即可能80%都会是true,或是false。
向前条件 / Forward conditional branches
1 | for (int i = 0; i < n; i++) { |
向后条件 / Backward conditional branches
1 | if (condition) { |
无条件跳转 / Unconditional branches
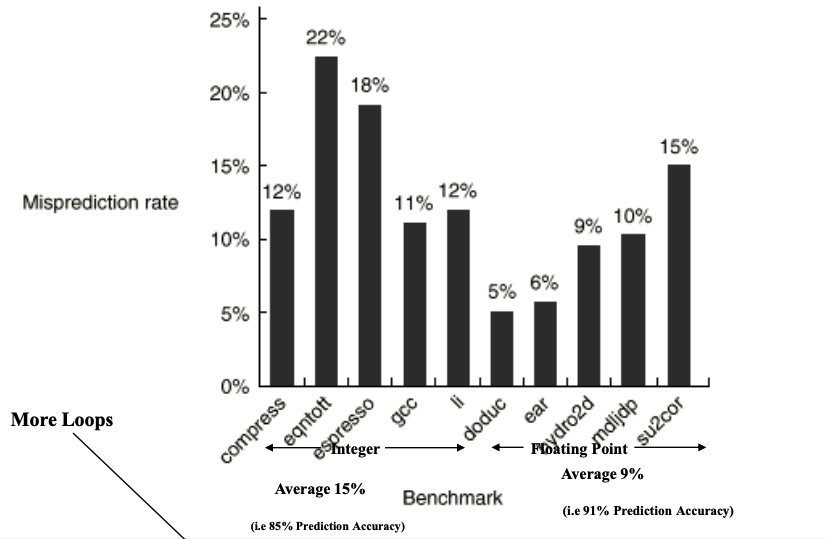
动态分支预测 / Dynamic Conditional Branch Prediction
动态分支预测相比于静态分支预测,最大的区别就是在运行的时候进行预测。一般对于结果的预测都是依赖于历史结果,也就是该条件前几次的执行结果进行统计。
这里描述几个简单的方案:
分支历史表 / Branch History Table (BHT)
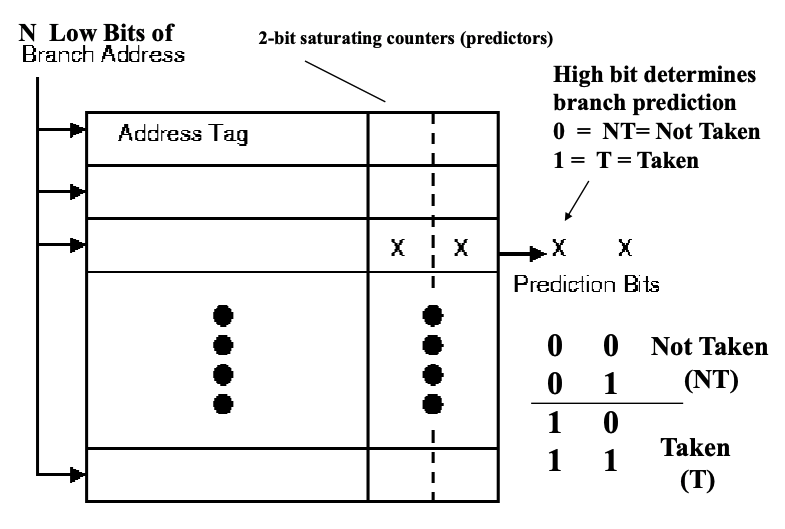
BHT中记录历史结果大小,可以为
1-Bit Prediction Quality
1 bit只能记录 taken 和 not taken 两种结果,在很多场合下会降低预测准确率,特别是在循环中。
2-Bit Branch-Prediction
2 bit就能记录4中状态:
- Strongly not taken
- Weakly not taken
- Weakly taken
- Strongly taken
这就需要2次不同的结果才能反转当前预测。当然可以选择更多 bit,但实验表明 2 bit 和 4096 个存储单元已经能够覆盖 82% - 99% 的场景了。
Two-Level Predictors and the GShare Algorithm
另外还有一些更为复杂的方案,比如2层的预测算法,这里就不做描述了。
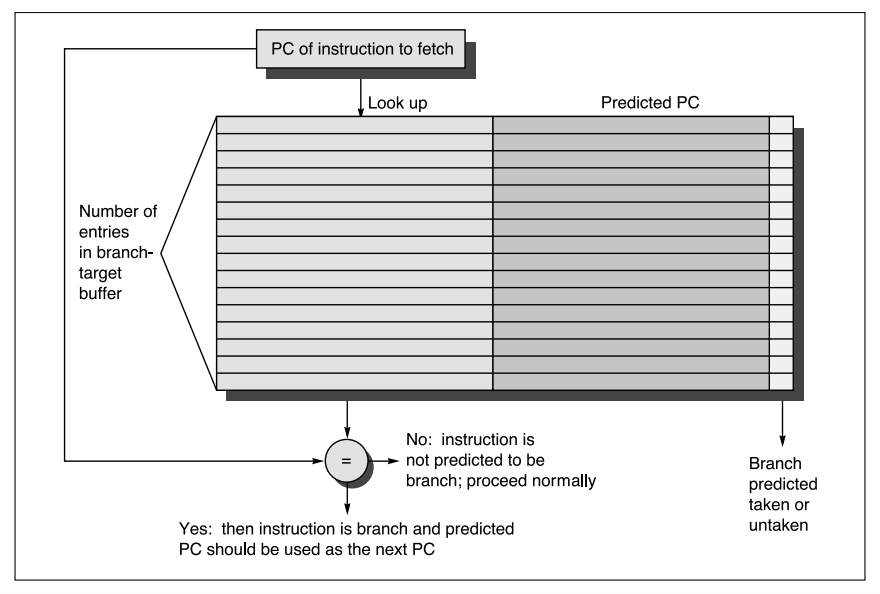
Branch Target Buffer (BTB)
另一种是BTB,这个表内存的是地址映射,也就是能够让我们在取指的时候就知道这是一个条件指令,那么下一个取指就可以根据该表得到预测的分支地址了。
一般情况下,我们需要在译码阶段才能知道该指令是否是条件指令,才能决定下一个指令是否需要分支预测,利用BTB可以继续提前一步。